Exploration 5 : 사람이 말하는 단어를 인공지능 모델로 구분해보자
1. 음성과 오디오 데이터
- 파동으로서의 소리 : 진폭, 주파수, 위상, 복합파
- 오디오 데이터의 디지털화 : 나이키스트-섀넌 표본화에 따라 Sampling rate가 결정되며, 일반적으로 사용되는 주파수 영역대는 16kHz, 44.1kHz이다.
- 표본화, 양자화, 부호화
2. Train / Test 데이터셋 구성하기
- Label data 처리
- 학습을 위한 데이터 분리 : sklearn.model_selection.train_test_split를 이용하기
- Data setting : one_hot, data.Dataset.from_tensor_slices, map, repeat, batch을 이용하기
3. Wave classification 모델 구현
- layers.input, layers.Conv1D, layers.MaxPool1D, layers.Dropout, layers.Flatten, layers.Dense, layers.BatchNormalization, layers.Activation, keras.Model
- Adam, CategoricalCrossentropy, ModelCheckpoint
- 학습 결과 plot 출력, evaluation, model test
4. Skip-Connection model 구현
- tf.concat([layer output tensor, layer output tensor], axis = )
- 나머지는 동일하게 구성
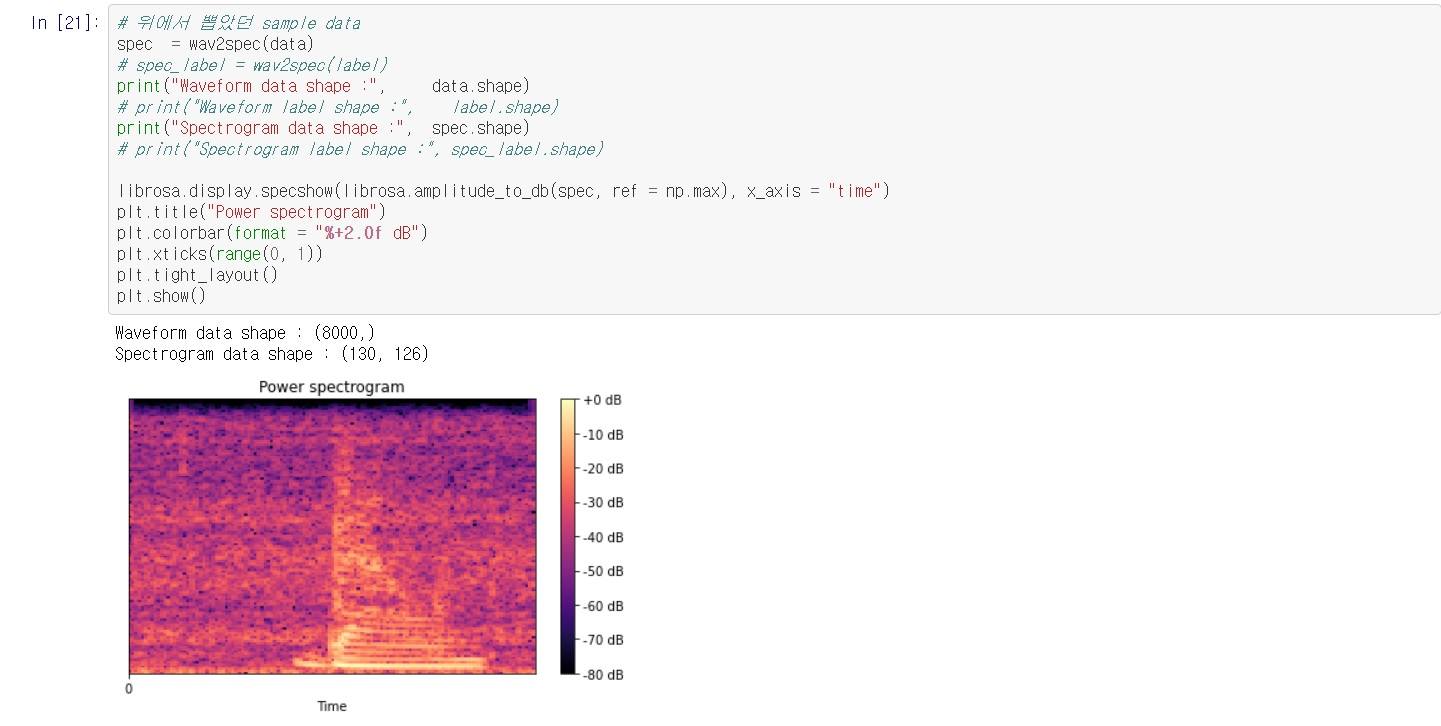
5. Spectrogram
- 푸리에변환(Fouroer transform), 오일러 공식, STFT(Short Time Fourier Transform)
- wav 데이터를 해석하는 방법 중 하나로, 일정 시간동안 wav 데이터 안의 다양한 주파수들이 얼마나 포함되어 있는지를 보여줌.
- librosa패키지를 이용하기
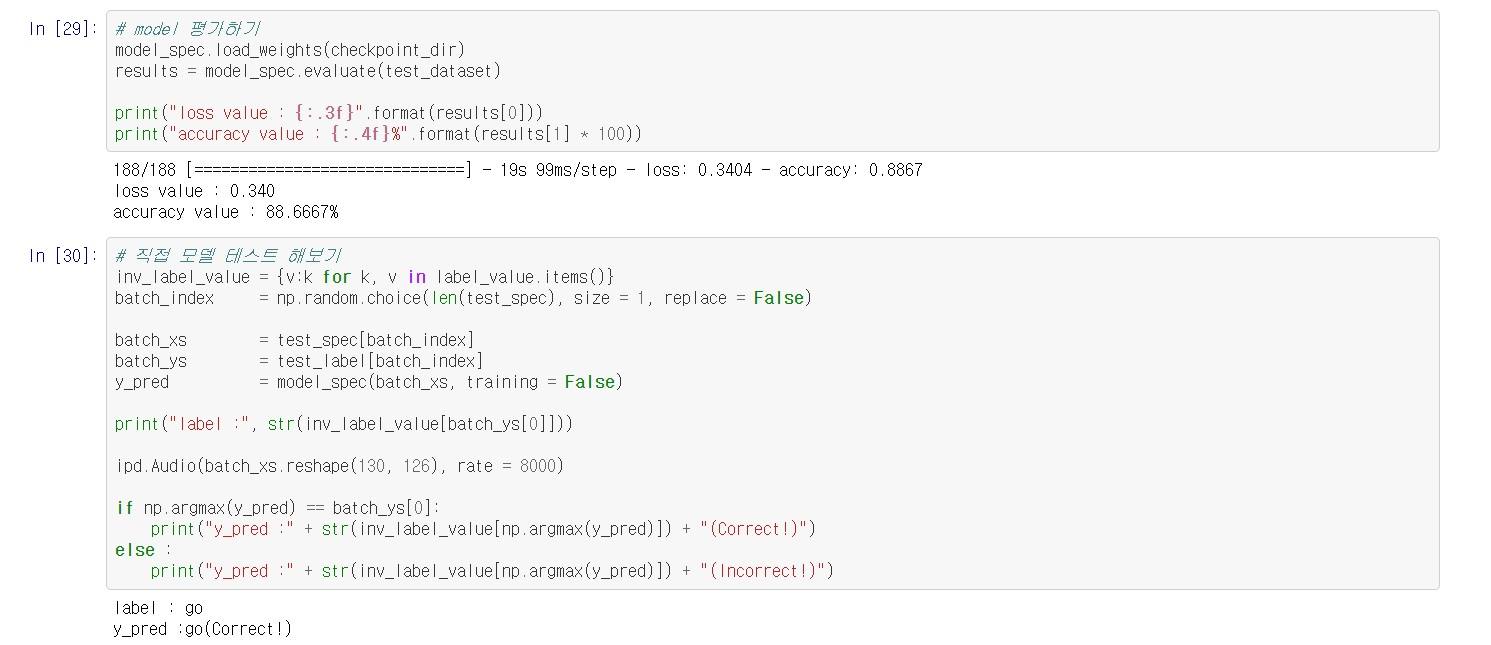
6. 프로젝트
- 위에서 1차원 wav 데이터를 가지고 모델을 만들고 학습 시키고 테스트 했는데
2차원 spectrogram 데이터로 변환한 뒤 모델을 사용하면 어떻게 될까?
- 성공적인것 같다.