1. 들어가며
- Human Pose Estimation with Keypoint detection
1) 틱톡이란 어플을 들어본 적이 있을 것이다. 전세계적으로 인기를 끌고 있는 어플리케이션 중 하나이다.
2) 여기서 카메라를 통해 다양한 효과를 줘서 인기를 끌고 있다.
3) 이는 지금까지 만들어본 얼굴인식 어플리케이션과 달리 전신이 등장하는 색다른 특징이 있다.
4) 나만의 카메라 어플을 스노우와 같은 얼굴인식 뿐만 아니라 더 넓은 범위로 사용할 수 있다면 좀 더 다양한 것을 만들 수 있을 것이다.
5) 오늘은 새로운 기능인 human pose estimation에 대한 개념과 이론에 대해 알아보도록 한다.
2. body language, 몸으로 하는 대화
- Human pose estimation(이하 HPE, 이는 공식용어가 아니다)은 크게 2D와 3D로 나뉜다.
- 2D HPE는 2D 이미지에서 (x, y) 2차원 좌표를 찾아내고, 3D HPE는 2D 이미지에서 (x, y, z) 3차원 좌표들을 찾아내는 기술이다.
- 그런데 2차원 이미지에서 3차원 이미지를 복원하는 일은 굉장히 어려운 일이다.
1) 2차원 이미지에서 3차원 이미지를 복원하는 일이 왜 어려울까?
(1) 직관적인 예시 : 2D 영상에서는 큰 원통이 멀리 있는 것과 작은 원통이 가까이 있는 것을 구분할 수 없다.
(2) 이론적인 설명 : 카메라 행렬에서 [x, y, z] real world 좌표가 이미지 [u, v] 좌표계로 표현될 때 z 축(거리 축) 정보가 소실되기 때문이다.
- 굉장히 어렵지만 사람의 몸은 3D 환경에서 제약이 있다.
- 현실세계 좌표계에서 발은 바닥에 있으면서 무릎은 머리 위로 갈 수 없듯이 말이다.
- 그래서 이런 제약 조건을 이용해서 어느정도 문제를 해결할 수 있다.
- 3D pose estimation을 깊이있게 다루기는 매우 오랜 시간이 걸리기 때문에, 오늘은 2D 영상 내에서 (x, y) pose(관절)의 위치를 찾는 방법을 다뤄본다.
3. Pose는 face landmark랑 비슷해요
- 이미 2D pose estimation을 다룬 적이 있다. face landmark와 비슷하다.
- 딥러닝이나 사람의 시각에서도 실제로도 매우 비슷한 어플리케이션이다. 입력과 출력이 개수만 다를 뿐 상당히 비슷하다.
- 하지만 난이도에서 차이가 난다. face landmark는 물리적으로 거의 고정되어 있는 반면(예를 들어 입은 얼굴보다 클 수 없다), human pose는 팔, 다리가 상대적으로 넓은 범위와 자유도를 갖는다는 것을 고려해야 한다.
- 자유도가 높다는 것은 데이터 분포를 특정하기 어렵다고 표현할 수 있을 것 같다.
- 데이터 분포를 학습하기 어렵다면 당연히 학습에 더 많은 데이터가 필요하고 더 복잡한 모델을 사용해야한다는 것을 의미한다.
- 따라서 상당히 많은 사전 작업이 요구되고 사용하려는 어플리케이션에 따라 접근 방법도 달라진다. 가장 초기에 만나는 접근법은 두 가지로 나눠질 수 있다.

- 우리에게 맞는 방법은 뭘까?
1) 첫 번째 방법은 Top-down 방법이다.
(1) 모든 사람의 정확한 keypoint를 찾기 위해 object detection을 사용한다.
(2) crop한 이미지 내에서 keypoint를 찾아내는 방법으로 표현한다.
(3) detector가 선행되어야 하고 모든 사람마다 알고리즘을 적용해야하기 때문에 사람이 많이 등장할 때는 느리다는 단점이 있다.
2) 두 번째 방법은 Bottom-up 방법이다.
(1) detector가 없고 keypoint를 먼저 검출한다. 예를 들어 손목에 해당하는 모든 점들을 검출한다.
(2) 한 사람에 해당하는 keypoint를 clustering 한다.
(3) detector가 없기 때문에 다수의 사람이 영상에 등장하더라도 속도 저하가 크지 않다. 반면 top down 방식에 비해 keypoint 검출범위가 넓어 성능이 떨어진다는 단점이 있다.
- 얼마나 정확해야 하는지, 여러 사람이 등장하는지 여부에 따라서 필요한 알고리즘이 달라질 수 있다.
- 핸드폰 카메라로 찍는 인물들은 대체로 소수로 등장하기 때문에 top-down 방식을 이용해도 큰 속도저하 없이 사용할 수 있을 것이라 생각한다.
- 그럼 Top-down 방법들에 대해 알아보도록 하자.
4. human keypoint detection (1)
- 위에서 설명한 것 처럼 human pose estimation은 keypoint의 localization 문제를 푼다는 점에서 비슷하다.
- 하지만 손목, 팔꿈치 등의 joint keypoint 정보는 얼굴의 keypoint보다 훨씬 다양한 위치와 변화를 보인다.

- 위 이미지는 움짤이니 밑에 url주소를 들어가면 볼 수 있다.
- 위 이미지에서 볼 수 있듯이 손이 얼굴을 가리는 행위, 모든 keypoint가 영상에 담기지 않는 등 invisible, occlusions, clothing, lighting change가 face landmark에 비해 더 어려운 환경을 만들어 낸다.
- 딥러닝 기반 방법이 적용되기 전에는 다양한 사전 지식이 사용 되었다.
- 가장 기본이 되는 아이디어는 인체는 변형 가능 부분으로 나누어져 있고 각 부분끼리 연결성을 가지고 있다는 것이다.

- 위 그림에서 보이는 것처럼 손은 팔, 팔은 몸과 연결되어 있다.
- 손이 다리 옆에 있을 확률이 팔 옆에 있을 확률보다는 작을 것이다. 이런 제약 조건을 그림에 보이는 스프링으로 표현했다.
- 3D 환경에서 생각하면 정말 좋은 방법이다.
- 하지만 우리가 다루는 데이터는 2D 이미지 데이터이기 때문에 촬영 각도에 따라 충분히 팔이 다리 옆에서 관찰될 수 있다.
- 이 문제를 해결하기 위해 Deformable part models 방법에서는 각 부분(part)들의 complex joint relationship의 mixture model로 keypoint를 표현하는 방법을 이용했지만 성능은 사람들의 기대에 미치지 못했다.
- 해당 논문을 보면 deformable part model은 template들의 모음으로 구성된다. template은 global과 part 두 가지 종류로 나누어져 있다고 써있다.
- DeepPose
1) 딥러닝 이전의 전통적 pose estimation 모델은 분명한 한계가 있다.
2) deformable parts model 논문에서 언급했듯이 graphical tree model은 같은 이미지에 두 번 연산을 하는 등 연산 효율이 떨어지는 점과 그에 비해서도 부족한 성능이 문제점으로 인식되어 왔다.
3) AlexNet 이후, 다양한 분야에서 CNN이 적용되면서 pose estimation 분야에도 CNN을 이용한 방법이 나타나기 시작했다.
4) Toshev and Szegedy는 처음으로 딥러닝 기반 keypoint localization 모델을 제안했다.

5) 기존 기술로는 풀기 어려웠던 동작의 다양성, invisible joint의 문제를 언급하며 딥러닝 기반 추론 방법이 해결책이 될 수 있다는 것을 증명해냈다.

6) 초기의 pose estimation 모델은 x, y 좌표를 직접적으로 예측하는 position regression 문제로 인식했다.
7) human detection을 통한 crop 된 사람 이미지를 이용해서 딥러닝 모델에 입력하고 (x, y) 좌표를 출력하도록 만든다.
8) position regression인 DeepPose는 어떤 loss 함수를 썼을까? -> L2 Loss를 사용했다.
9) DeepPose는 매우 혁신적인 시도였던 것에 비해 사실 성능이 압도적으로 높았던 것은 아니다.

10) 위 표에서 볼 수 있듯이 DeepPose가 전반적으로 높은 성능을 나타내고 있긴 하지만 기존 Tree based model인 Wang et al의 방법에 비해 비약적으로 성능을 상승시켰다고 말하기는 어렵다.
11) DeepPose의 기여는 SOTA에 가까운 성능을 내면서도 딥러닝을 적용한 첫 번째 사례라고 할 수 있다.
- Efficient Object Localization Using Convolutional Network
1) DeepPose는 딥러닝을 사용했는데 왜 성능이 비약적으로 상승하지 않았을까?
2) 여기서는 해결책으로 한 논문을 제시한다.

3) Tompson이 제안한 Efficient object localization 방법을 간단하게 소개해본다.
4) 이 논문에서는 제안했던 모델도 DeepPose에 비해 깊어졌지만, 가장 중요한건 keypoint의 위치를 직접 예측하기보다 keypoint가 존재할 확률 분포를 학습하게 하자는 점이다.

5) human pose (keypoint)도 사람이 labeling을 할 수 밖에 없는데 사람이 항상 같은 위치의 점을 찍을 수 있을까?
6) 위의 움짤을 보면 쉽게 관찰할 수 있다. keypoint들을 유심히 바라봐보자.
7) 귀는 귀에 눈은 눈에 keypoint 자체는 잘 찍혀있는 것 같은데 두 동영상에 차이가 있는 듯 하다.
8) Kalman filter 라고 적힌 동영상에 비해 Orig measured는 점이 굉장히 떨리고 있는 것을 확인할 수 있다.
9) 항상 같은 위치라고 생각하면서 keypoint를 선택하지만 사실 매 사진마다 수 픽셀씩 차이가 생기고 있다.
10) 눈을 찍고 싶다면 눈을 중심으로 어떤 분포의 에러가 더해져서 저장되는 것이다.
11) 자연상태에서 일어나는 확률 분포는 가우시안 분포일 가능성이 크다.
12) Tompson은 이런 점에 착안하여 label을 (x, y) 좌표에서 (x, y)를 중심으로 하는 heatmap으로 변환 했다.
13) 딥러닝 모델은 이 heatmap을 학습하게 되는 것이다.
14) keypoint가 존재할 확률을 학습하게 된 이후로 성능이 비약적으로 향상되는 것을 볼 수 있다.
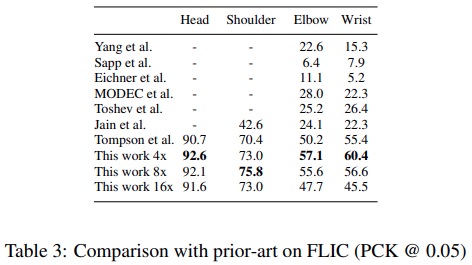
15) Toshev가 제안한 DeepPose에 비해 2배가 넘는 수치를 확인할 수 있다. 머리의 경우 95가 넘는 높은 성능을 가진다.

16) MPII 데이터는 2014년에 나온 데이터이다.
17) 기존 FLIC 데이터가 머리, 어깨, 팔꿈치, 손목 수준의 적은 개수의 keypoint를 가지고 있었지만 MPII는 몸의 각 관절부위 16개의 keypoint를 갖는다.
18) 이는 기존 논문(Gkioxari, Sapp)들이 일부 데이터가 없는 이유이다. 이 데이터셋에 대해서는 다음에 자세히 다룰 예정이다.
19) Tompson이 제안한 방법은 heatmap 학습 뿐만이 아니다.
20) 모델에서도 개선을 이뤘다. 어떤 방법이 있는지는 논문을 확인하자. (Efficient Object Localization Using Convolutional Networks)

21) Tompson이 제안한 모델은 Coarse model과 fine model로 나뉜다. 두 모델 간에 어떤 관계가 있을까?
(1) Coarse model에서 32x32 heatmap을 대략적으로 추출한 후 multi resolution 입력을 coarse heatmap 기준으로 crop 한 뒤 fine model에서 refinement를 수행한다.
22) Tompson이 제안한 모델에서 weight sharing이 적용된 부분을 설명해보자. 왜 이렇게 만들었을까?
(1) coarse model과 fine model이 같은 모델이며 weight를 공유한다.
(2) 목적이 같기 때문에 빠른 학습이 가능하고, 메모리와 저장공간을 효율적으로 사용할 수 있다.
5. human keypoint detection (2)
- Convolutional Pose Machines
1) CVPR 2016에서 발표된 CPM은 completely differentiable한 multi-stage 구조를 제안했다.
2) multi stage 방법들은 DeepPose에서부터 지속적으로 사용되어 왔다.
3) 하지만 crop 연산 등 비연속적인 미분불가능한 stage 단위로 나눠져 있었기 때문에 학습 과정을 여러번 반복하는 비효율적인 방법을 사용해왔다.
4) CPM은 end-to-end로 학습할 수 있는 모델을 제안한다.

5) Stage 1은 image feature를 계산하는 역할을 하고 stage 2는 keypoint를 예측하는 역할을 한다.
6) g1과 g2 모두 heatmap을 출력하게 만들어서 재사용이 가능한 부분은 weight sharing 할 수 있도록 세부 모델을 설계했다.

7) 위 이미지 (d)에서 볼 수 있듯이 stage 2 이상부터는 반복적으로 사용할 수 있다.
8) 보통은 3개의 스테이지를 사용한다고 한다.
9) stage 1구조는 고정이고, stage 2부터는 stage 2 구조를 반복해서 추론한다.
10) stage 2부터는 입력이 heatmap(image feature)이 되기 때문에 stage 단계를 거칠수록 keypoint가 refinement 되는 효과를 볼 수 있다.

11) 사실 CPM이 아주 좋은 방법이라고는 말하기 어렵다.
12) Multi-stage 방법을 사용하기 때문에 end-to-end로 학습이 가능하더라도 그대로 학습하는 경우는 높은 성능을 달성하기 어렵다.
13) 따라서 stage 단위로 pretraining을 한 후 다시 하나의 모델로 합쳐서 학습을 한다.
14) 논문을 작성하기 위해서라면 충분히 감내할 수 있지만 서비스에서 보면 불편한 요소라고 할 수 있다.
15) 이런 문제점들은 이후에 제안되는 모델들이 개선하고 있다.
16) CPM을 다루는 이유는 성능 때문이다. receptive field를 넓게 만드는 multi stage refinement 방법이 성능 향상에 크게 기여한 것 같다.

17) 위 그림을 보면 주황색 실선이 Tompsom 알고리즘이다.
18) CPM에서 제안한 검정색, 회색 실선이 detection rate에서 유의미한 차이를 보이고 있는 것을 볼 수 있다.
19) MPII의 PCKh@0.5(x축)에서 87.95%를 달성했다고 한다. 당시 2등보다 6.11%p 더 높은 성능을 보인 것이다.
- Stacked Hourglass Network
1) ECCV 16에서는 DeepPose 이후 랜드마크라고 불릴만한 논문이 제안되었다.
2) 바로 Stacked Hourglass Networks for Human Pose Estimation이라는 논문이다.
3) 이름에 모든 내용이 담겨있으니 하나하나 살펴보자.
4) 먼저 Hourglass이다.
5) Stacked Hourglass Network의 기본 구조는 모래시계 같은 모양으로 만들어져 있다.
6) Conv layer와 pooling으로 이미지(또는 feature)를 인코딩 하고 upsampling layer를 통해 feature map의 크기를 키우는 방향으로 decoding한다.
7) 이렇게 feature map 크기가 작아졌다가 커지는 구조여서 hourglass라고 표현한다.

8) 이 방법과 기존 방법들과의 가장 큰 차이점은 아래와 같다.
(1) feature map upsampling
(2) residual connection
9) pooling으로 image의 global feature를 찾고 upsampling으로 local feature를 고려하는 아이디어가 hourglass의 핵심 novelty라고 할 수 있다.
10) Hourglass의 모델 구조를 보면 U-Net이 생각날 수 있다. 실제로 두 모델의 구조가 비슷하다.
11) Hourglass는 이 간단한 구조를 여러 층으로 쌓아올려서(stacked) human pose estimation의 성능을 향상시켰다.

12) MPII에서 처음으로 PCKh@0.5 기준 90%를 넘어서는 성과를 보이게 된다.
13) 특유의 간단한 구조와 높은 성능으로 현재까지도 많이 사용되고 있는 구조이다. human pose 분야에 관심이 있다면 한번 사용해 보는 것을 권장한다.
- SimpleBaseline
1) 앞서 소개한 연구들은 딥러닝 기반의 2D human pose estimation이 어떻게 발전했는지 보여주고 있다.
2) (x, y)를 직접 regression하는 방법이 heatmap 기반으로 바뀌고 모델의 구조가 바뀌어 가면서 encoder-decoder가 쌓아져 가는 형태가 완성되었다.
3) 결과적으로 MPII에서 90%를 넘길 정도로 좋아졌지만 모델의 구조는 복잡해졌다. (현재 시점에서 나오는 모델들과 비교하면 아니지만...)
4) HPE의 연구를 쭉 따라오던 당시 마이크로소프트 인턴 Haiping Wu는 다른 시각을 가졌다.
5) 기술 자체가 많이 발전했는데 현재의 간단한 모델은 얼마나 성능이 좋을까? 라는 시각이였다.
6) SimpleBaseline의 저자는 정말 아주 간단한 encoder-decoder 구조를 설계한다.

7) 그리고 이 구조로 73.7%의 mAP를 COCO에서 달성한다. 직전 연도인 2017년의 72.1% 결과를 뛰어넘은 수치였다. 인턴 성과로 ECCV 2018에 출판되는 위엄을 보여주게 된다.

8) 직전 방법인 hourglass와 직접 비교해보면 아래와 같은 결과가 나온다.

9) resnet50만 사용한 간단한 구조가 hourglass와 같은 SOTA(stage-of-the-art)를 이겼다는 것에 큰 놀라움을 준 논문이라 생각한다.
10) 참고로 CPN은 이전에 소개한 Convolutional Pose Machine이 아닌 Cascaded Pyramid Network라는 모델이다.
11) 자세히 소개하지는 않지만 skip connection이 stage 사이에 연결되어 있다는 정도만 이해하고 넘어가자.
12) SimpleBaseline은 구조가 간단하기 때문에 다뤄보기 좋을 것 같다. 그래서 다음 스텝에서 코드로 해봤다.
- Deep High-Resolution Network (HRNet)
1) HRNet은 개발된 이후 현재까지도 SOTA에 가까운 성능을 보일 정도로 성능이 좋은 알고리즘이다.
2) SimpleBaseline의 1저자가 참여해 연구한 모델이기 때문에 SimpleBaseline과 같은 철학을 공유한다.
3) Stacked hourglass, cascaded pyramid network 등은 multi-stage 구조로 이뤄져 있어서 학습 & 추론 속도가 느리다는 단점이 있다.
4) 그래도 하이퍼파라미터를 최적화할 경우 1-stage 방법보다 성능은 좋아진다.
5) 반면 SimpleBaseline과 HRNet은 간단함을 추구하는 만큼 1-stage를 고수한다. 덕분에 구조도 간결해지고 사용하기도 쉽다.

6) 위 그림을 보면 19년까지 COCO 데이터셋에서 SOTA의 성능을 자랑한다.
7) 1-stage에서 어떻게 모델을 변화시켰을까? 먼저 기존 알고리즘들을 살펴보자.

8) 위 그림에 대해 보면 (a) : Hourglass, (b) : CPN(cascaded pyramid networks), (c) : SimpleBaseline - transposed conv, (d) : SimpleBaseline - dilated conv를 나타낸다.
9) 위 그림에서 SimpleBaseline이 다른 알고리즘에 비해 성능이 떨어지지 않지만 구조를 보면 공통점과 차이점을 관찰할 수 있다.
(1) 공통점 : high resolution -> low resolution인 encoder와 low -> high인 decoder 구조로 이루어졌다.
(2) 차이점 : Hourglass는 encoder와 decoder의 비율이 거의 비슷하다(대칭적이다). 반면 SimpleBaseline은 encoder가 무겁고(resnet50 등 backbone을 사용) decoder는 가벼운 모델을 사용한다.
(3) 차이점 : (a), (b)는 skip connection이 있지만 (c)는 skip connection이 없다.
10) 차이점에 조금 더 집중해보면 기존 모델들은 skip connection을 적극적으로 사용했다.
(1) 왜 사용했을까? -> pooling(strided conv)할 때 소실되는 정보를 high level layer에서 사용해서 detail한 정보를 학습하기 위해 사용한다.
(2) SimpleBaseline도 사용해야 하지 않을까? -> 당연히 사용할 때 성능이 더 좋을 것이다.
11) HRNet 저자도 앞의 질문들에 대해 고민을 했다. high -> low -> high의 구조에서 high resolution 정보(representation)을 유지할 수 있는 모델을 어떻게 만들었을까?

12) 그 결과, down sample layer를 만들고 작아진 layer feature 정보를 다시 upsampling해서 원본 해상도 크기에 적용하는 모델을 제안했다.
13) 다소 복잡해 보이지만, 1-stage로 동작하기 때문에 전체 flow를 보면 엄청 간단하다.
14) 우리가 앞에서 다뤘던 CPM이나 Hourglass는 중간 단계에서의 heatmap supervision이 학습 과정에 꼭 필요했는데 HRNet은 필요가 없다.
15) 구현도 SimpleBaseline의 backbone인 Resnet을 HRNet으로 교체만 해주면 되기 때문에 사용하기도 굉장히 편리하다.
16) HRNet 또한 이전 알고리즘들과 마찬가지로 heatmap을 regression하는 방식으로 학습하고 MSE loss를 사용한다.
17) 아래의 이미지로 결과를 살펴보면, 앞에서 다뤘던 SimpleBaseline이 보이고, CPN도 보인다.

18) AP 성능을 보면 HRNet이 4%에 가까운 비약적인 성능향상을 이뤘다.
19) 비교적 학습이 간단하면서 성능까지 좋은 모델이여서 현재도 많이 사용되고 있다. 특히 원저자의 PyTorch 코드가 매우 깔끔하게 구현되어 있고, 재생산성이 높아 사용하기 좋다.
20) https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
6. 코드로 이해하는 pose estimation
- 오늘 본 6개의 모델이 잘 이해가 되는가? 아마 글로만 읽어서 크게 와닿지 않을것이다.
- 백문이 불여일견이라 하였다. 시각적으로 표현했을 때 한 번에 이해할 수 있다는 점이 영상처리의 가장 큰 장점인 것 같다.
- 코드도 마찬가지이다. 잘 작성된 코드는 하나의 예술작품처럼 아릅답게 보이고 오히려 더 직관적으로 보인다.
- 6개 모델 중 가장 간단한 모델인 SimpleBaseline을 모델 부분만 정확하게 이해해 보겠다.
- SimpleBaseline 구조

1) 그림을 통해
(1) encoder : conv layers
(2) decoder : deconv module + upsampling
2) 으로 이루어져 있다는 것을 알 수 있지만 conv layer가 정확히 어떻게 이루어져 있는지, deconv module은 어떻게 구성되어 있는지, deconv module이 위 그림처럼 3개일지는 논문을 읽어야지 알 수 있는 부분이다.
3) 그럼 논문에 대한 질문 몇가지를 아래에서 해본다.
4) conv model로 어떤 backbone을 사용하는가? -> ResNet을 사용한다.
5) deconv module은 어떤 레이어로 이루어져 있는가?
(1) deconv -> bn -> relu 이 단계가 3개로 이루어져 있다.
(2) deconv는 256 filter size, 4x4 kernel, stride 2로 2배씩 feature map이 커진다.
6) 마지막 출력 레이어는 어떤 레이어로 구성되어있나? -> k개의 1x1 conv layer로 구성되있다.
- PyTorch code 읽어보기
1) 사실 논문도 모든 디테일을 설명해 주지 않는다.
2) 하지만 인공지능 분야의 최대 장점은 저자의 공식 코드가 제공된다는 점이다.
3) 마침 SimpleBaseline의 저자도 논문에서 코드 repo의 위치를 언급했다.
4) https://github.com/Microsoft/human-pose-estimation.pytorch
5) 18년 이후 PyTorch의 급격한 성장이 있었다. 오늘 볼 코드도 PyTorch 기반으로 작성되어 있다.

6) 파이토치 코드를 읽을 줄 모른다면 그만큼 참고할 코드가 줄어든다는 것을 의미한다.
7) 이번 스텝만으로 파이토치 코드를 구현할 수 없더라도 지금까지 쌓아온 기본기를 이용해서 SampleBaseline의 파이토치 코드를 읽어보도록 한다.
8) 코드를 통해 실습했다.
'공부 > AIFFEL' 카테고리의 다른 글
| 2021년 5월 10일 모두의 연구소(인공지능 전문가 과정) - 90일차 (0) | 2021.05.10 |
|---|---|
| Going Deeper(CV)_DJ 20 : 행동 스티커 만들기 (0) | 2021.05.07 |
| Going Deeper(CV)_DJ 18 : 멀리 있는 사람도 스티커를 붙여주자 (0) | 2021.05.05 |
| Going Deeper(CV)_DJ 16 : 불안한 시선 이펙트 추가하기 (0) | 2021.05.03 |
| Going Deeper(CV)_DJ 15 : 내 거친 생각과 불안한 눈빛과 그걸 지켜보는 카메라앱 (0) | 2021.04.29 |