1. 들어가며
- ML Coarse-to-Fine 전략과 Active Learining 기초
- 머신러닝 서비스를 만들 때 가장 중요한 것은 무엇일까?
- 가장 중요한 것 하나만 뽑으라고 한다면 데이터라고 말하고 싶다.
- 그러나 우리가 만들고자 하는 머신러닝 서비스에 꼭 맞는 데이터셋을 늘 구할 수 있는 것은 아니다.
- 오히려 그런 이상적인 경우는 극히 드물다고 봐야된다.
- 현실 문제에 부딪혔을 때 우리는 모델을 어떻게 만들거냐 보다는 훨씬 많은 시간을 데이터를 어떻게 수집, 가공할 것이냐의 문제로 고민하게 될 것이다.
- 언제나 그렇듯 확보한 데이터의 갯수는 턱없이 부족하고, 이를 메꾸기 위한 예산은 확보되어 있지 않으며, 서비스 딜리버리 타임은 얼마 남지 않은 현실을 우리는 어떻게 헤쳐 나갈 수 있을까?
- 그래서 이번 시간은 머신러닝 엔지니어가 늘 고민해 오는 문제, 바로 데이터를 효율적으로 모으는 방법에 대해 이야기 해보자.
2. 카메라앱에 당황한 표정 효과를 추가하려면?
- 만화를 보면 캐릭터가 당황할 때 나오는 표정이 보통 아래의 그림과 같이 재미있게 표현한다. 이를 카메라앱으로 구현하려면 어떻게 해야 할까?

- 짐작했을 수 있겠지만, 우선 눈을 찾아야 한다.
- 기본적으로 랜드마크(landmark)를 이용해 눈의 위치를 찾는 방법은 알고 있을 것이라 생각한다.
- 하지만 일반적인 랜드마크는 눈이 바라보고 있는 방향까지는 포함하고 있지 않다.
- 아래의 사진처럼 시선의 방향이 왼쪽으로 향하고 있다는 정보를 이용하려 한다.

- 어떻게 해결할 수 있을까? 눈동자의 위치를 알 수 있다면 더 섬세한 표현이 가능할 것을 예상할 수 있다.
- 눈동자를 찾는 방법
1) 그러면 눈동자를 쉽게 찾는 방법이 있을까?
2) dlib와 같은 오픈소스 라이브러리는 눈의 외각선 위치만 찾아줄 뿐 시선을 나타내는 눈동자는 찾아주지 않는다.
3) 우리는 눈의 외곽선 정보를 사용해 눈을 찾아내고 그 내부에서 눈동자를 검출하는 것이 목표이다. 아래의 그림처럼.

4) 문제를 해결하기 위해 눈동자 검출 데이터셋을 찾아보자.

5) 대체로 위와 같은 데이터셋을 찾을 수 있을 것이다. 위 이미지는 Labeled pupils in the wild : A dataset for studying pupil detection in unconstrained environments에서 나온 것이다.
6) 이 데이터셋은 눈동자 검출과 관련이 있는 데이터이지만 우리가 목표로 하는 촬영 환경과 많이 다르다.
7) 우리는 보통 사진을 찍으면 핸드폰을 가지고 팔을 쭉 펴고 촬영을 한다. (거리가 있는 촬영 환경)
8) 하지만 이 데이터셋은 AR 기기를 위한 10cm 이내의 근거리 촬영 환경이다.
9) 실제 서비스를 만들 때에도 우리가 만들고 싶은 환경에 꼭 맞는 데이터셋을 찾기는 매우 어렵다.
10) 따라서 머신러닝 개발자는 공개된 데이터와 모델이 모두 없을 때 문제를 접근하는 방법에 대해 고민하고, 해결책을 찾을 수 있는 능력이 요구된다.
11) 딥러닝 기반 방법을 적용하려면 아주 많은 데이터가 필요하다.
12) 자본이 많은 상황이라면 데이터와 주변 환경을 구매하는 방법으로 해결할 수 있다.
13) 하지만 처음 시도하는 업무에 대규모 자본을 투자하기에는 현실적으로 어려움이 있다. 돈이 있다해도 성공할 수 있을지 모르고, 성과를 낼 수 있는지도 모르기 때문이다.
14) 따라서 초기 컨셉 증명 단계에서는 소규모의 자본과 인력으로 프로토타입을 만들어야하는데 이 때 딥러닝을 적용하기 쉽지 않다.
15) 기존 머신러닝 방법을 적절히 이용하는 방법과 잘 가공된 어노테이션(annotation) 도구를 만들 수 있다면 바로 딥러닝 방법을 적용하는 것보다 빠르게 문제를 해결할 수 있을 것이다.
16) 그래서 오늘 배울 것은 아래와 같다.
(1) 기존 머신러닝 방법을 적용한 눈동자 검출 모듈을 만드는 방법에 대해 설명한다.
(2) 딥러닝 방법을 이용한 눈동자 검출 모듈을 제작한다.
(3) 앞에서 만들어진 데이터와 함께 높은 품질의 라벨을 얻을 수 있는 라벨링 툴(labeling tool)에 대해 설명한다.
(4) 마지막으로 앞의 과정을 어떻게 효율적인 순서로 진행할 수 있는지 논의한다.
3. 대량의 Coarse Point Label 모아보기 (1) 도메인의 특징을 파악하자
- 딥러닝을 적용하지 않고 머신러닝 방법을 이용한다는 말은 곧 handcraft feature(사람이 정의한 특징)을 사용해야 한다는 말과 같다.
- 이 때 모델이 사용할 특징을 정의하기 위해서는 해당 분야에 대한 이해가 필요하다. 즉, 도메인 전문가가 좋은 모델을 만들 확률이 높다는 뜻이다.
- 이 방법이 어떻게 적용될 수 있고 왜 필요한지 예시를 통해 알아보자.
1) 노드의 필자는 2018년에 알츠하이머 치매 진단 보조 솔류션을 만들었다.
2) MRI를 촬영한 후 뇌 조직을 분석해서 알츠하이머 환자와 정상군의 분포를 파악하는 업무를 진행했다고 한다. 이 때 다양한 치매의 종류를 접할 수 있었고 그 중 한 사례를 말했다.
3) 혈관성 치매(Vascular Dementia)는 뇌혈관 문제로 뇌조직이 손상을 입게 되어 발생하는 치매이다.
4) 치매는 현재 치료법이 없기 때문에 발병을 미리 예측하고 대비해서 진행을 늦추는 방법이 최선이다.
5) 그 만큼 조기 진단으로 병의 분류와 원인을 찾는 것이 중요하다.
6) 다른 알츠하이머와 마찬가지로 이 경우도 MRI 이미지를 통해 진단을 도울 수 있다.
7) MRI에는 T1w, T2w, FLAIR 등 다양한 촬영 방식(protocol)이 있다. 아래의 이미지를 통해 FLAIR 이미지를 한 장 살펴보자.

8) 처음보면 어디가 정상이고 어디가 문제인지 전혀 파악할 수 없다.
9) 이 이미지에서는 어디가 회백질이고, 어디가 백질인지 구분이 잘 되지 않는다.
10) 사실 FLAIR 이미지에서는 백질과 회백질을 구분하기 어려운 대신 뇌척수액과 같은 물은 비교적 구분하기 쉽다.
11) 아래의 그림을 보자.

12) 빨간색 영역과 같이 뇌척수액 부분은 주변보다 흰 값으로 나타나게 된다.
13) 뇌혈관에 문제가 생기게 되면 피 등의 액체가 백질에 스며들게 되고 뇌조직에 문제가 생길 수 있다.
14) 백질이 보다 밝은 값으로 나타난다고 해서 WMH(White Matter Hyperintensity)라고 한다.
15) WMH가 있다고 반드시 문제가 생기는 것은 아니지만 문제가 생긴 환자 중 많은 사례까 WMH를 가지고 있다.
16) 그래서 뇌의학 선생님들은 WMH를 찾는 것을 중요하게 생각하고 있다.
17) 그래서 WMH를 자동으로 찾아야 했는데 문제는 라벨이 마땅하지 않았다. (지금은 오픈 데이터가 조금씩 생기고 있다고 한다.)
18) 세그멘테이션(segmentation)은 라벨링(labeling)이 어렵기 때문에 초기에 딥러닝을 사용하지 않는 방법을 사용해야 했다.
19) 이 문제는 생각해보면 아주 쉽게 초기 모델(baseline)을 만들어볼 수 있다.

20) WMH의 뜻을 다시 생각해 보면, 이름처럼 하얗게 표시되는 부분은 높은 픽셀 값을 가지고 있다.
21) 그러므로 255 번위 내에서 200 이상의 값을 가지는 픽셀들만 찾아내면 간단한 초기 모델을 만들 수 있다.
22) 이렇게 초기 모델을 만들고 이 데이터를 바탕으로 딥러닝 모델을 학습시켜 나가면 좋은 성과를 얻을 수 있다.
- 이렇게 근사적인(coarse) 데이터셋을 간단히 만들고, 이를 이용해 초기 모델을 만든 후 그 모델을 더욱 정교하게 훈련시켜가는 전략을 ML Coarse-to-Fine 전략이라고 한다.
- 이 이야기에서 중요한 점은
1) 풀고 싶은 도메인의 지식을 익힌다 -> 혈관성 치매와 WMH, MRI에서 어떤 패턴은 보이는지
2) 딥러닝이 아닌 방법을 적용할 수 있는 능력이 있는지 -> Image threshold 등 영상처리 기법이 있는지
- 등을 생각하고 적용할 수 있어야 한다는 것이다.
4. 대량의 Coarse Point Label 모아보기 (2) 가우시안 블러
- 다시 문제로 돌아와서, 눈동자에는 어떤 특징이 있을지 고민해 보자.
- WMH와 반대로 눈동자는 어둡다. 어두운 부분의 중간을 찾으면 될까?
- 좋은 아이디어다. 물론 더 좋은 방법이 있다는 사실을 늘 염두에 두어야 한다.
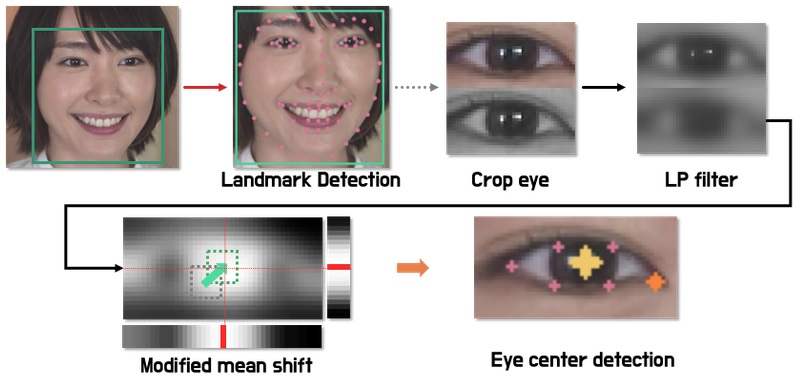
- 랜드마크(landmark)을 이용해서 눈을 crop 하고 눈에서 가장 어두운 부분의 중심을 찾는다.
- 눈동자에 빛이 반사되는 경우가 있는데 노이즈(noise) 성분을 없애기 위해 가우시안 블러(gaussian blur)를 적용했다. (대체적으로 눈동자가 어두운 경향을 따르기 위해서 노이즈를 없앤다.)
- 가우시안 블러는 어떤 종류의 필터(filter) 인가? 위키 페이지의 소제목에서 잘 찾아보자
1) 저역 통과 필터(Low pass filter)로 고주파 신호를 감쇄시키는 필터이다.
2) 현재 픽셀값과 주변 픽셀값의 가중 평균을 사용해서 현재 픽셀을 대체한다.
- 가우시안 블러는 어떤 숫자들로 이루어져 있나? 예시로 3x3 행렬을 써보자.
1) [[1, 2, 1], [2, 3, 2], [1, 2, 1]] 이런 식으로 가중치 행렬을 이용해 구현할 수 있다.
- 아래 사진은 블러 후 흑백을 반전 시킨 이미지이다. 여기서 가장 높은 값을 갖는 픽셀을 고르면 아래 그림처럼 눈의 위치를 찾을 수 있다.

- 가장 높은 값의 기준은 여러 방향으로 정의할 수 있다.
- 2D 이미지 상에서 바로 (x, y) 위치를 추정하는 방법(argmax(x, y)(image))이 있을 수 있고 위 그림에서 오른쪽과 아래 부분에 보이듯이 1차원으로 누적하는 방법도 있다.
- 위 2차원 이미지에서 눈의 중심 부분 근처 픽셀은 거의 모두 255로 최대값을 나타낸다.
- 따라서 눈동자를 특정하기가 어려운데, 가우시안 블러를 적용하면 눈동자 중심을 평균으로 하는 가우시안 분포를 볼 수 있다.
- 물론 최대값 255로 truncate 되어 있고, 눈동자만 밝은 것이 아니기 때문에 mixture density처럼 나타나진다.
- 이 때 1차원으로 누적해서 표현하면 255로 truncated 되는 문제와 주변 노이즈에 조금 더 강건하게 대처할 수 있다.
5. 대량의 Coarse Point Label 모아보기 (3) 구현 : 눈 이미지 얻기
- 코드 실습으로 학습했다.
6. 대량의 Coarse Point Label 모아보기 (4) 구현 : 눈동자 찾기
- 코드 실습으로 학습했다.
7. 키포인트 검출 딥러닝 모델 만들기
- 이제 더 나은 성능을 위해 딥러닝 모델을 만드는 것을 고려해야 한다.
- 앞에서는 도메인 지식을 활용해서 수작업으로 특성들을(hand-crafted features) 만들었다면 이제부터는 도메인 지식 없이 뉴럴넷이 특징을 자동으로 뽑을 수 있도록 설계한다.
- 지금까지 우리는 VGG, Resnet 등 기본(base) 모델을 이미지 분류 문제를 위해 사용해 왔다.
- 주로 수십 개 이내의 클래스 중 하나를 찾는 문제에 적용했는데 이 모델을 우리의 목표인 눈동자로 변형해 줘야 한다.

- 이미지 분류 모델은 이미지를 CNN에 입력해서 최종적으로 해당 클래스의 인덱스를 찾아낸다.
- 즉, 모델의 출력은 클래스를 나타내는 단일 idx 값(또는 one-hot vector)이 된다.
- 눈동자 위치를 찾기 위해서 아래와 같은 구조로 모델을 변경해야 한다.

- 가장 먼저, 출력의 개수가 변경된다. 이미지 분류 문제에서는 소프트맥스(softmax)를 통과해 1개의 클래스 인덱스를 출력했지만 눈동자 중심 위치인 x, y 좌표를 출력해야 한다.
- 이 때 값은 분류 모델의 정수형 불연속 값이 아닌 연속형 값이여야 한다. 이런 문제를 회구(regression) 문제라고 한다.
- 각 태스크의 출력 특징
1) Image Classification : argmax(softmax)의 불연속 정수형 값
2) Image Localization(regression) : 연속형 실수 값
- 소프트맥스 - 크로스 엔트로피(cross-entropy) 방법은 이미지 클래스를 구분하기 위해 사용하는 가장 대표적인 손실 함수이다.
- 회귀에서는 어떨까? 여러 개의 값이 연속형 실수로 출력되어야 하기 때문에 MSE와 같은 손실 함수를 고려할 수 있다.

- 이제 만든 모델을 학습시키면 된다. 이론적으로는 학습시키면 된다. 하지만 실전은 항상 더 어렵다.
- 내 needs에 꼭 맞는 커스텀 태스크의 경우는 데이터가 대부분 부족하다. 오늘 강의에서도 높은 퀄리티의 눈동자 라벨을 얻기가 꽤 어렵다는 사실을 느꼈다.
- 이런 경우에 접근할 수 있는 방법은 미리 학습된 가중치(weight)를 가지고 와서 fine tuning 하는 것이다.
- 가져온 가중치가 학습된(pretrained) 태스크가 나의 태스크와 같은 도메인이면 더 좋겠지만 아니어도 효과는 있다.
- 그래서 보통은 이미지넷(ImageNet)이나 COCO 데이터셋으로 학습한 모델 가중치를 가져와서 fine tunung한다.

- 이후 학습은 코드로 진행했다.
8. 라벨링 툴 (1) 소개
- 이전 단계에서 coarse label로 모델을 어느 정도 수준까지 만들었다.
- 이제 fine label을 얻어서 모델을 향상시켜야 할 때이다.
- 양질의 라벨을 빠르게 얻기 위해선 어노테이션 툴(annotation tool) 또는 라벨링 툴(labeling tool)을 사용해야 한다.
- 잘 알려진 비전 태스크(image classification, object detection, semantic segmentation)는 공개된 어노테이션 도구가 많다.
- OpenCV의 CVAT은 이미지 검출(object detection) 등에 이용할 수 있고 무료로 공개되어 있다.
- imglab이라는 툴도 공개되어 있다. COCO 데이터셋 형태로 저장할 수 있고 키포인트 라벨링(keypoints labeling)도 할 수 있다.
- 무료로 공개된 이미지 어노테이션 툴을 2가지 더 찾아보자.
1) labelimg (github.com/tzutalin/labelImg)
2) labelme (github.com/wkentaro/labelme)
- 여러 어노테이션 도구들을 살펴보면 몇 가지 특징을 알 수 있다.
1) QT 등의 GUI 프레임워크를 이용하는 방법과 웹 기반 방법으로 나누어 진다.
2) 단축키와 라벨 저장 포멧 등 편의성을 향상시킬 수 있는 기능을 적극적으로 적용한다.
- 높은 편의성을 앞세워서 공개하고 있지만 막상 사용해보면 우리가 원하는 태스크에 딱 맞지 않는 경우가 대부분이다. (3D 환경에서 세그멘테이션 해야 하는 일 등)
- 우리는 눈동자의 위치를 선책할 수 있는 도구가 필요하다. imglab에는 키포인트(keypoint) 도구가 있기 때문에 사용해 볼 수는 있다.
- 하지만 문제는 COCO 데이터셋에서 라벨링한 스타일을 지켜야하기 때문에 17개의 키포인트를 정해야 하는 규칙이 있다는 점이다.
- 우리는 눈동자 1개를 찍거나 양 눈 옆 2개의 점이 필요한데 이 조건에 꼭 맞는 라벨링 도구를 만나기는 쉽지 않다.
- 결국 일을 하다 보면 나에게 맞는 도구를 직접 만들게 된다. 마침 적절한 제작기가 있다.
1) Linewalks - Data tech company for healthcare system
- Linewalks에서는 어떤 영역(도메인) 문제를 해결하기 위해 어노테이션 툴을 제작했나?
1) 의료 분야(안저영상)의 진단 보조 시스템
- Linewalks의 저자는 어노테이션 툴을 만들기 위해 어떤 프레임워크를 사용했나? 해당 프레임의 장점은 무엇인가?
1) electron을 사용했다.
2) 웹 개발자가 익숙한 언어로 바로 사용할 수 있기 때문에 학습 장벽이 낮다.
3) cross platform이다.
- 문제는 나를 포함한 초보자들은 웹 프레임워크나 GUI 프로그래밍에 익숙하지 않다는 점이다.
- 라벨링 툴을 제작하려 생각하다보면 QT, MFC, HTML/CSS/JavaScript를 익히고 어플리케이션 수준까지 만들 고민을 하는 상황을 맞이하게 된다.
- 머신러닝 엔지니어 입장에서는 배보다 배꼽이 더 큰 상황이 되므로 상당한 부담을 느끼게 된다.
- 따라서 가장 간단하고 효율적인 형태로 라벨링 툴을 제작해야 한다. 라벨링을 할 때 두 단계로 라벨링을 하고 있다.
1) 기존에 만들어진 라벨이 잘 예측하는지 True / False 분류
2) 해당 태스크의 어노테이션 툴 (우리의 경우 키포인트 어노테이션)
- 오늘 다룰 눈동자 검출은 1, 2번 모두 OpenCV만을 이용해서 아주 간단하게 만들 수 있다. 이번에는 1번만 만들어 보겠다.
9. 라벨링 툴 (2) 직접 제작하기
- 코드 실습으로 학습했다.
10. Human-in-the-loop & Active Learning
- 이번 스텝에서는 지금까지 만들어온 학습 시스템을 한눈에 정리해보고 학습 시스템을 어떻게 만들면 효율적인지, 라벨링을 어떤 시점에서 시작해야 하는지 살펴본다.
- 가장 먼저 시선 검출을 위해 모델들을 설계했다. 전처리 후 키포인트 검출 모델을 만들어서 눈동자 위치를 예측했다.
- Coarse 데이터셋 만들기

1) 데이터가 없는 업무 초반에는 mean shift와 같은 머신러닝 방법들을 이용해서 coarse한 예측 결과를 만들 수 있다.
2) 이 예측 결과는 딥러닝 모델에 학습 데이터로 사용할 수 있었다.
- Fine Dataset 만들기

1) coarse dataset은 라벨 자체의 정확도가 떨어지기 때문에 fine한 라벨을 얻을 수 있도록 개선시켜야 한다.
2) 가장 간단하게 라벨링할 수 있는 방법은 기존 결과가 좋다 또는 나쁘다로 분류하는 것이다.
3) 결과가 좋고 나쁜 것을 기록해 두면 그 자체로도 라벨이 된다.
4) 이 정보를 이용해서 이미지 분류기(classifier)를 만들 수가 있다.
5) 이 때 CAM(class activation map)을 추가하면 어디가 잘못되었는지 조금 더 쉽게 관찰할 수 있다.
6) Class Activation Map(Learning Deep Features for Discriminative Localization)의 논문을 참고하면 된다.
7) CAM의 계산 방법을 설명해보자.
(1) CNN을 통과한 logit을 GAP해서 채널 수 별로 embedding 한다.
(2) embedding layer에 클래스 개수만큼 fully connected layer를 통과시킨다.
(3) 이 때 FC layer의 weight와 logit의 가중합을 계산하면 CAM을 얻을 수 있다.
8) 만들어진 분류기는 fine label을 만들 때 효과적으로 사용할 수 있다.
9) 예측 결과가 좋음으로 나온 결과는 fine한 라벨이라 생각하고 학습시킬 수 있고
10) 반면 나쁨으로 나오면서 CAM 결과도 좋지 않다면 라벨링을 했을 때 효과적인 데이터셋을 만들 수 있을 것이다.
- Active Learning
1) 위 개념이 바로 액티브 러닝(active learning)의 방법론의 시작이다.
2) 라벨링을 할 때 어떤 데이터를 선정할 것인지 고민하고 사람에게 모델이 피드백을 주는 학습방법이라고 생각할 수 있다.
3) 이렇게 뽑아진 후보군을 직접 라벨링 한다.

4) 우리가 만들 라벨링 툴을 사용해서 양질의 라벨로 만들어낸다.
5) 저는 이 데이터셋을 fine dataset이라 부르고 있다.
6) 만들어진 데이터셋으로 다시 학습을 시키면 모델 개선의 반복문이 만들어진다.

7) 학습하고 다시 예측하면서 모델의 성능을 효율적으로 끌어올리는 방법이다.

8) 사람이 학습시스템에 가장 효율적으로 개입하는 방법(human-in-the-loop), active하게 학습 데이터를 추출하고 라벨을 개선시키는 방법에 대해 알아봤다.
9) 모델 자체를 잘 설계하는 것도 중요하지만 머신러닝 엔지니어라면 어떻게 하면 데이터를 효율적으로 모을 수 있을지 잘 고민해야 한다고 생각한다.
'공부 > AIFFEL' 카테고리의 다른 글
| Going Deeper(CV)_DJ 18 : 멀리 있는 사람도 스티커를 붙여주자 (0) | 2021.05.05 |
|---|---|
| Going Deeper(CV)_DJ 16 : 불안한 시선 이펙트 추가하기 (0) | 2021.05.03 |
| Going Deeper(CV)_DJ 14 : 카메라 스티커앱을 개선하자! (0) | 2021.04.27 |
| Going Deeper(CV)_DJ 13 : 내가 만든 카메라앱, 무엇이 문제일까? (0) | 2021.04.26 |
| Going Deeper(CV)_DJ 12 : 직접 만들어보는 OCR (0) | 2021.04.23 |